{Insights}
by alchemain team


There’s no real debate anymore about whether AI can refactor code.
If you take a single repository, point an AI coding assistant at it, and ask it to upgrade a dependency, the results are often impressive. It can trace usage, update method calls, fix imports, and adjust for API changes with a level of speed that would have felt unrealistic even a year ago. Combined with a scanner, it can identify vulnerable or outdated libraries and propose a path forward almost instantly.
In a contained environment, this works because the problem is bounded. The assistant has access to the full codebase, the dependency manifests, and the local usage of each library. The feedback loop is tight: generate a change, compile, run tests, inspect failures, and iterate. Even when things go wrong, a developer is there to intervene, refine the prompt, or guide the system toward a working solution.
That combination of local context and human-in-the-loop iteration is what makes the experience feel reliable. But if you look a bit deeper, it is also exactly what prevents it from scaling.
A Single Repo is Small Fry
The moment you move beyond a single repository, the nature of the problem changes in ways that most AI-assisted workflows are not designed to handle. What began as a code transformation task at small scale becomes a distributed systems problem at organizational scale.
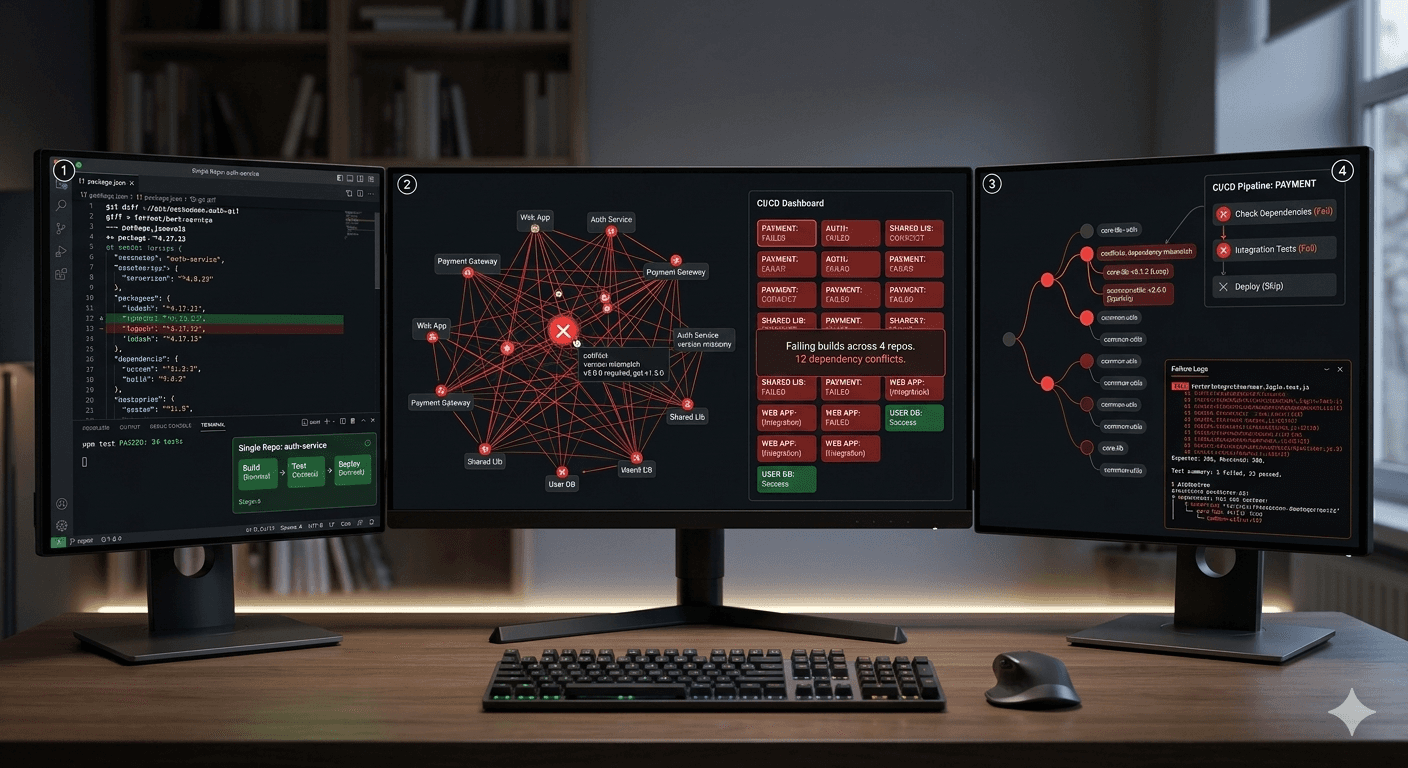
The first issue is context fragmentation. AI assistants operate within the boundary of a single repository. They can reason about the abstract syntax tree, follow symbol references, and understand how a dependency is used within that codebase. What they cannot see is how that same dependency is used across dozens of other services, or how internal libraries propagate version constraints through an organization. In practice, dependencies are not isolated; they form a graph that spans repositories, build systems, and runtime environments.
That graph is not just large, it’s constantly shifting at resolution time. Modern applications pull in hundreds or thousands of transitive dependencies, many resolved dynamically through build tools like Maven or Gradle. A single version change can trigger conflict resolution, override rules, or dependency evictions that alter the final classpath in non-obvious ways. A minor update in a deeply nested library can change method signatures, introduce stricter type requirements, or shift runtime behaviour, only surfacing as failures several layers upstream. In a single repository, you can trace and fix that breakage directly. At scale, those effects propagate across services, pipelines, and environments that may not share ownership or release cycles.
Getting Real About the Limitations of Prompt-driven Workflows
AI coding assistants are fundamentally reactive. They depend on a developer to initiate the task, provide sufficient context, and evaluate the output. Even when integrated with scanners, the workflow remains linear: detect an issue, generate a fix, validate it locally, and attempt to merge. Each step requires human intervention, and each execution is shaped by how that individual developer frames the problem, what context they include, and what constraints they implicitly assume. Even small differences in prompts can lead to materially different refactors, especially when dealing with ambiguous API migrations or overloaded method signatures.
Across an org, this leads to divergence. Different engineers will choose different upgrade paths, apply different prompts, and accept different levels of risk. There is no guarantee that two repositories depending on the same library will converge on the same version or even remain compatible. Instead of standardization, you can get drift.
The operational consequences of this are already well understood. Dependency upgrades fail frequently on the first attempt, not because version bumps themselves are inherently complex, but because they introduce API incompatibilities that require coordinated changes to first-party code. Most automated pull requests generated by existing tools still require manual fixes before they can be merged . AI assistants can accelerate parts of that process, but they do not remove the coordination problem. They simply make each individual attempt faster.
What’s missing is not intelligence at the point of code generation, but control over the system as a whole.
Our 00felix Can Leave Your AI Assistant in the Dust
At scale, the problem is no longer “can we generate the right refactor for this file?” It becomes “can we apply a consistent, validated transformation across an entire dependency graph, spanning multiple repositories, without breaking downstream systems?” That requires properties that interactive tools do not provide. But we know a clever secret agent fox who was born for exactly that.

First, 00felix is autonomous. As long as upgrades depend on developers to trigger scans, interpret results, and guide refactoring, the system inherits human variability. This is manageable in isolation, but it does not produce consistent outcomes across hundreds of codebases.
Second, 00felix has full graph awareness. Understanding direct dependencies is insufficient; the majority of breakages originate from transitive changes that are not visible at the top level. Without modelling the full dependency graph and how it resolves at build time, any upgrade strategy is inherently incomplete.
Third, 00felix doesn’t change depending on his mood, he’s pretty deterministic. Given the same starting state and target version, your solution should produce the same result regardless of where or how it is run. This is essential for maintaining compatibility across services and avoiding version skew.
Finally, and most importantly, 00felix validates his own output, he never leaves you with a mess. Generating a syntactically correct refactor is not enough. The only meaningful signal is whether the system compiles, passes tests, and behaves correctly under the target runtime conditions. Achieving that requires an iterative feedback loop: apply changes, compile, run tests, analyse failures, and refine the transformation until a stable state is reached. This is the part of the workflow that is still largely manual today, and it is the part that determines whether an upgrade is actually usable.
Ask Yourself: Does My Solution Scale?
AI coding assistants are effective at augmenting developers, but they are not designed to own multi-step, system-wide processes. Dependency management at scale is one of those processes. It spans detection, planning, transformation, validation, and delivery, and it needs to operate consistently across an entire organisation.
This is where the distinction between an assistant and a system becomes important. An assistant helps you perform a task. A system ensures that the task is completed correctly, every time, without requiring continuous human intervention.
Refactoring code in response to dependency changes is no longer the hard part. Can AI do it? Of course it can. But can it achieve that reliably, across every repository, in a way that keeps builds green and environments consistent? Because that is where the real complexity lies. And that’s the problem that actually needs solving.
Curious about a scalable solution for software dependency management? Learn more about Alchemain’s 00felix by scheduling a 30-min no obligation demo and chat with our CEO, Ali N.


